Foundation Models gelten im Forecasting als nächster großer Entwicklungsschritt: Ein vortrainiertes Modell soll auf sehr unterschiedlichen Zeitreihen brauchbare Vorhersagen liefern, ohne dass für jede Reihe ein eigenes Modell trainiert werden muss. In der Praxis stellt sich jedoch schnell die entscheidende Frage: Reicht Zero-Shot-Forecasting aus oder lohnt sich ein Finetuning auf dem eigenen Datensatz?
In diesem Beitrag ordnen wir ein, was Foundation Models im Forecasting ausmacht, wie sie sich von klassischen Verfahren unterscheiden und unter welchen Bedingungen ein Finetuning echten Mehrwert liefert.
Was sind Foundation Models im Forecasting?
Was unterscheidet Foundation Models von klassischen Forecasting-Verfahren?
Welche Foundation Models prägen das Forecasting aktuell?
Wann lohnt sich Finetuning und wann genügt Zero-Shot-Forecasting?
Wie entwickeln sich Foundation Models im Forecasting weiter?
Was sind Foundation Models im Forecasting?
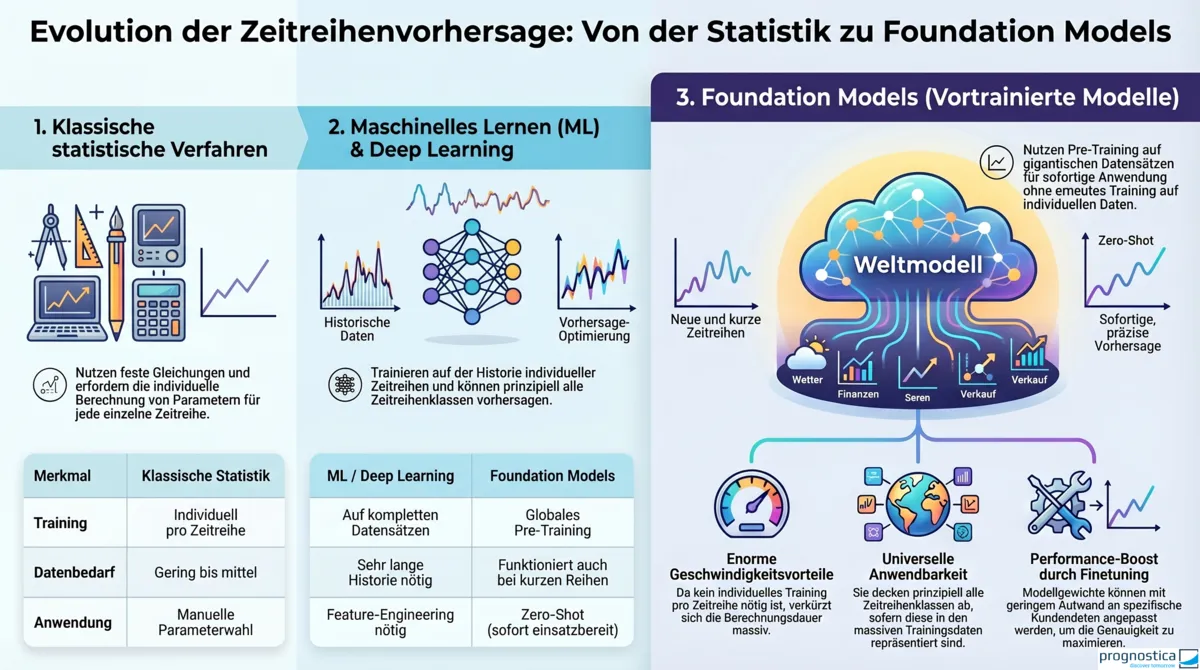
Foundation Models im Forecasting sind vereinfacht gesagt so etwas wie Large Language Models (LLMs) für Zeitreihen: große, vortrainierte Modelle, die auf umfangreichen Datensätzen allgemeine Muster lernen und dadurch für viele unterschiedliche Forecasting-Aufgaben einsetzbar sind. Während LLMs Sprache verarbeiten, erkennen Foundation Models typische Strukturen in Zeitreihen, etwa Trends, Saisonalitäten und wiederkehrende Muster.
Möglich wurde diese Entwicklung unter anderem durch die Transformer-Architektur mit ihrem parallelisierbaren Self-Attention-Mechanismus, die durch Anwendungen wie ChatGPT seit November 2022 einer breiten Öffentlichkeit bekannt wurde. Der Erfolg dieses Ansatzes, der auf sehr großen Modellen mit einer hohen Anzahl an Parametern und gigantischen Trainingsdatensätzen basiert, hat gezeigt, dass sich große, vortrainierte Modelle nicht nur für Text, sondern auch für andere Datentypen eignen, etwa für Bilder, Audio und eben für Zeitreihen.
Im Forecasting werden solche Modelle auf großen und möglichst diversen Zeitreihen-Datensätzen trainiert. Ziel ist es, auf einer breiten Bandbreite unterschiedlicher Zeitreihenklassen kompetitive Vorhersagen zu liefern, ohne dass für jede einzelne Zeitreihe ein eigenes Modell trainiert werden muss.
Was unterscheidet Foundation Models von klassischen Forecasting-Verfahren?
Um zu verstehen, was Foundation Models im Forecasting besonders macht, lohnt sich zunächst ein Blick auf die Verfahren, die bisher typischerweise in der Zeitreihenvorhersage eingesetzt werden. Klassische statistische Verfahren wie ARIMA (Autoregressive Integrated Moving Average) werden für jede Zeitreihe individuell trainiert. Dabei werden Zusammenhänge aus der Historie der jeweiligen Zeitreihe gelernt und in Modellparametern abgebildet, etwa der Einfluss vergangener Werte oder saisonaler Effekte. Auf Basis dieser Parameter lassen sich dann zukünftige Werte genau dieser Zeitreihe berechnen.
Mit dem Aufkommen des maschinellen Lernens kamen weitere Ansätze hinzu. Feature-basierte globale Modelle wie Regressionsbäume oder Random Forests werden nicht mehr für jede Zeitreihe einzeln trainiert, sondern auf einem gesamten Datensatz von Zeitreihen. Dafür müssen dem Modell jedoch geeignete Merkmale manuell zur Verfügung gestellt werden. Welche Features sinnvoll sind, erfordert fachliches Wissen und Erfahrung.
Bei Deep-Learning-Modellen wie dem LSTM (Long Short-Term Memory) werden solche Merkmale nicht mehr händisch definiert, sondern direkt aus der zeitlichen Sequenz gelernt, indem die Gewichte des neuronalen Netzes angepasst werden. Damit dieses automatische Lernen gut funktioniert, ist in der Regel jedoch eine deutlich längere Historie erforderlich als bei klassischen oder feature-basierten Verfahren. Das begrenzt den Einsatzbereich dieser ansonsten oft sehr leistungsfähigen Modelle. Hinzu kommt, dass Deep-Learning-Modelle nach dem Training in der Regel stark auf die Zeitreihen des jeweiligen Trainingsdatensatzes zugeschnitten sind. Ohne erneutes Training sollten sie deshalb nicht ohne Weiteres auf gänzlich andere Zeitreihenklassen übertragen werden. Unter einer Zeitreihenklasse versteht man dabei Gruppen von Zeitreihen mit ähnlichen Eigenschaften, etwa sporadische Zeitreihen oder saisonale Zeitreihen.
Foundation Models unterscheiden sich davon in mehreren Punkten:
Sie sind ebenfalls globale Modelle, benötigen aber keine manuell konstruierten Features. Die Historie der Zeitreihe reicht als Eingabe aus, um Vorhersagen zu erzeugen. Merkmale wie Trend oder Saisonalität müssen also nicht zuerst separat aus den Daten berechnet und dem Modell übergeben werden.
Foundation Models können auch auf sehr kurze Zeitreihen angewendet werden. Das ist möglich, weil sie auf großen und möglichst vielfältigen Zeitreihen-Korpora vortrainiert werden, die unterschiedliche Zeitreihenklassen abdecken sollen. Die dabei gelernten Muster werden in den Modellparametern gespeichert und können anschließend auch auf neue Zeitreihen übertragen werden.
Soll ein Foundation Model eine neue Zeitreihe vorhersagen, ist dafür in vielen Fällen kein zusätzliches Training auf genau dieser Zeitreihe notwendig. Stattdessen kann die Vorhersage allein auf Basis ihrer Historie erfolgen. Man spricht dann von einer Zero-Shot-Vorhersage. Genau darin liegt das zentrale Versprechen von Foundation Models im Forecasting: Ein einziges Modell kann prinzipiell für sehr unterschiedliche Forecasting-Aufgaben und Zeitreihenklassen eingesetzt werden. Das Erzeugen von Forecasts geht dann außerdem sehr schnell, da nicht wie bei traditionellen Ansätzen häufig mehrere Modelle trainiert und anschließend anhand ihrer Performance auf der Historie verglichen werden, was die Berechnung entsprechend aufwändig macht.
Welche Foundation Models prägen das Forecasting aktuell?
Im Laufe der Zeit wurden von verschiedenen Anbietern zahlreiche Foundation Models für das Forecasting veröffentlicht. Eine vollständige Übersicht ist in diesem Rahmen nicht möglich. Stattdessen geben wir einen kurzen Einblick in einige zentrale Ideen und technische Ansätze, durch die sich die Modelle voneinander unterscheiden.
TimesFM: Patches statt einzelner Werte
Eine der frühen Herausforderungen bei Foundation Models für Zeitreihen war die große Kontextlänge. Zeitreihen mit täglicher, stündlicher oder noch feinerer Granularität umfassen oft mehr als 1.000 Datenpunkte. Um auch Abhängigkeiten über längere Zeiträume hinweg abbilden zu können, fasst TimesFM von Google mehrere aufeinanderfolgende Werte einer Zeitreihe zu sogenannten Patches zusammen und behandelt diese als Tokens. Tokens sind die kleinsten Einheiten, auf denen das Modell arbeitet. Anders als bei LLMs, bei denen einzelne Wörter oder Wortteile tokenisiert werden, entsprechen Tokens hier also ganzen Abschnitten einer Zeitreihe. Auch die Forecasts werden patchweise ausgegeben, wobei die Ausgabepatches in der Regel länger sind als die Input-Patches. Damit kurzfristige Dynamiken trotz dieser Verdichtung erhalten bleiben, überlappen sich die Patches. Das lässt sich grob mit der Arbeitsweise von Faltungsoperationen in der Bildverarbeitung vergleichen.
Statt Zeitreihen als aufeinander folgende Datenpunkte zu sehen, übersetzt man die Zeitreihe sozusagen in eine Sprache, die ein ganz eigenes Vokabular besitzt. In dieser Sprache könnte ein Satz beispielsweise lauten: “Die Zeitreihenwerte sind gerade ganz schön hoch. Da geht es jetzt noch höher.”
Chronos: Quantisierung für kontinuierliche Werte
Zeitreihenwerte sind kontinuierlich und können theoretisch unendlich viele Ausprägungen annehmen. Chronos von Amazon begegnet diesem Problem, indem die Werte zunächst skaliert und anschließend in diskrete Wertebereiche quantisiert werden. Die Zeitreihe wird damit in eine Folge diskreter Tokens übersetzt, die ähnlich wie Sprache modelliert werden kann. Für die Vorhersage werden die Output-Tokens anschließend wieder in den ursprünglichen Wertebereich zurückgeführt.
TimeGPT und synthetische Trainingsdaten
Ein weiterer wichtiger Aspekt ist die Zusammensetzung der Trainingsdaten. Wie bei Foundation Models jeglicher Art werden auch im Forecasting öffentlich verfügbare Datensätze genutzt. TimeGPT von Nixtla wurde beispielsweise auf einer sehr großen Zahl von Zeitreihen aus unterschiedlichen Domänen trainiert. Ergänzend kommen häufig synthetische Daten zum Einsatz, etwa im Rahmen von Datenaugmentierung, um unterrepräsentierte Zeitreihenklassen besser abzudecken. Solche synthetischen Zeitreihen stammen nicht aus realen Anwendungsfällen, sondern werden regelbasiert erzeugt, zum Beispiel in Form von Sinuskurven mit festgelegter Amplitude, Frequenz und Phase.
Gerade bei Zeitreihen mit externen Kovariaten besteht allerdings weiterhin ein Mangel an geeigneten Trainingsdaten. Deshalb gibt es bislang kein Foundation Model, das Kovariaten bereits systematisch direkt im Pretraining berücksichtigt.
Warum sich Foundation Models derzeit nur schwer vergleichen lassen
Welches Foundation Model im Forecasting das beste ist, lässt sich derzeit kaum eindeutig beantworten. Dafür gibt es mehrere Gründe:
- Neue Modelle und Modellversionen erscheinen in hoher Geschwindigkeit.
- Bewertungen stützen sich häufig auf öffentlich zugängliche Benchmark-Datensätze, deren Aussagekraft nur eingeschränkt belastbar ist. Mit der ersten Evaluation sind Benchmark-Datensätze ebenfalls öffentlich verfügbar. Dadurch steigt bei neueren Modellen die Wahrscheinlichkeit, dass sie zumindest auf Teilen dieser Benchmarks trainiert wurden. Das verschafft ihnen potenziell einen unfairen Vorteil gegenüber älteren Modellen, die vor Veröffentlichung des Benchmarks entwickelt wurden.
- Nicht alle Anbieter legen offen, auf welchen Daten ihre Modelle trainiert wurden. Da die Zusammensetzung der Trainingsdaten einen Wettbewerbsvorteil darstellen kann, bleibt oft unklar, ob ein Modell tatsächlich besser ist oder ob es bereits Teile des Benchmark-Datensatzes gesehen hat.
Als Reaktion darauf werden laufend neue Benchmarks zusammengestellt und veröffentlicht, um solchen Verzerrungen entgegenzuwirken. Genau das macht den Vergleich jedoch zusätzlich unübersichtlich: Je mehr Benchmarks entstehen, desto schwieriger wird es, Modelle dauerhaft und fair miteinander zu vergleichen.
Wann lohnt sich Finetuning und wann genügt Zero-Shot-Forecasting?
Foundation Models können bereits ohne zusätzliche Anpassung sinnvolle Vorhersagen liefern. Ob dafür Zero-Shot-Forecasting ausreicht oder ein Finetuning sinnvoll ist, hängt vor allem von den Eigenschaften des eigenen Datensatzes und den Anforderungen an die Prognosequalität ab.
Wann reicht Zero-Shot-Forecasting ohne Finetuning aus?
Für ihre breite Anwendbarkeit werden Foundation Models auf möglichst diversen Datensätzen vortrainiert. Ziel ist es, für eine große Bandbreite unterschiedlicher Zeitreihenklassen bereits ohne zusätzliche Anpassung passable Forecasts zu ermöglichen. Zero-Shot-Forecasting kann daher insbesondere dann ausreichen, wenn
- das vortrainierte Modell auf dem eigenen Datensatz bereits eine ausreichende Vorhersagequalität erreicht,
- der Anwendungsfall keine hochgradig spezifischen Muster aufweist und
- ein schneller, ressourcenschonender Einsatz im Vordergrund steht.
Das ist vor allem in frühen Evaluationsphasen relevant oder dann, wenn Forecasts für viele unterschiedliche Zeitreihen mit möglichst geringem Implementierungsaufwand erzeugt werden sollen.
Wann ist Finetuning sinnvoll?
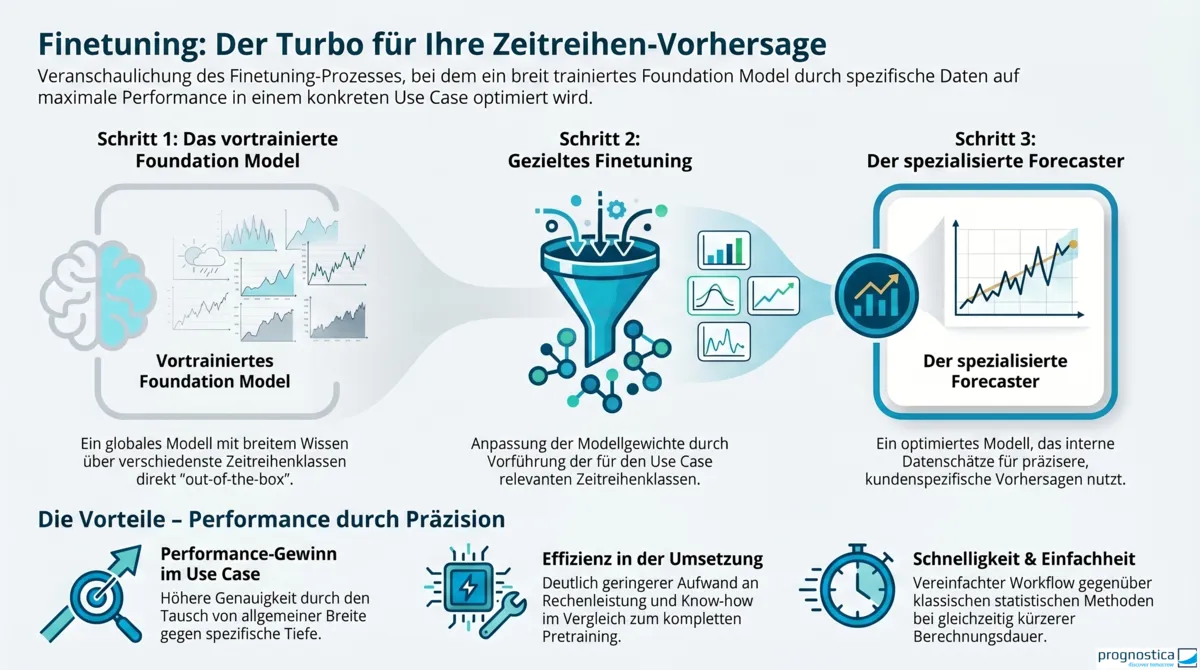
Im produktiven Einsatz ist der eigene Datensatz häufig deutlich homogener als die Datenbasis, auf der ein Foundation Model vortrainiert wurde. Vielleicht haben alle Zeitreihen dieselbe Granularität, stammen aus derselben Branche oder enthalten immer wieder sehr ähnliche, datensatzspezifische Muster. In solchen Fällen kann Finetuning sinnvoll sein.
Beim Finetuning werden die Modellgewichte in einem nachgelagerten Training gezielt an den eigenen Anwendungsdatensatz angepasst. Vereinfacht gesagt wird ein Teil der allgemeinen Generalisierungsfähigkeit gegen eine bessere Spezialisierung auf den eigenen Use Case eingetauscht.
Finetuning lohnt sich insbesondere dann, wenn
- zusätzliche Performance-Gewinne geschäftlich relevant sind,
- der eigene Datensatz klar abgegrenzte Eigenschaften aufweist,
- genügend qualitätsgesicherte Trainingsdaten für den Zielkontext vorliegen,
- Zero-Shot bereits brauchbar ist, aber noch nicht das benötigte Qualitätsniveau erreicht.
Bereits heute konnten wir in diversen unserer Projekte zeigen, dass sich durch Finetuning verborgene Potenziale in unternehmensinternen Daten erschließen lassen.
Wichtig ist dabei: Finetuning ist deutlich weniger aufwändig als das ursprüngliche Pretraining eines Foundation Models, aber es ist dennoch kein Selbstläufer. Datenaufbereitung, saubere Evaluationslogik und die Wahl geeigneter Metriken bleiben entscheidend.
Wie entwickeln sich Foundation Models im Forecasting weiter?
Die Entwicklung geht aktuell in mehrere Richtungen gleichzeitig:
Ein wichtiger Trend sind multimodale Foundation Models. Solche Modelle verarbeiten nicht nur Zeitreihen selbst, sondern auch zusätzliche Informationen wie Texte, Events oder Bilder. Für Unternehmen ist das besonders relevant, weil wertvolle Vorhersagesignale oft nicht in klassischer Zeitreihenform vorliegen.
Darüber hinaus zeichnen sich Ansätze ab, die die Einbindung externer Einflussgrößen in die Vorhersage erleichtern sollen. Dazu gehören etwa dem eigentlichen Modell vorgeschaltete, vergleichsweise leicht trainierbare Adaptoren. Auch das Cross-Learning datensatzspezifischer Muster gewinnt an Bedeutung und wurde beispielsweise bereits in Chronos 2 aufgegriffen: Zum Beispiel können dann sehr kurze Zeitreihen stärker von ähnlichen Zeitreihen innerhalb derselben Produktgruppe oder Kategorie profitieren.
Es spricht daher vieles dafür, dass Foundation Models im Forecasting in Zukunft nicht nur leistungsfähiger, sondern auch flexibler einsetzbar werden. Gerade für Unternehmen dürfte es sich deshalb zunehmend lohnen, das Potenzial der eigenen Datenbasis im Zusammenspiel mit diesen Modellen gezielt zu erschließen.
Wie finden Unternehmen das richtige Foundation Model?
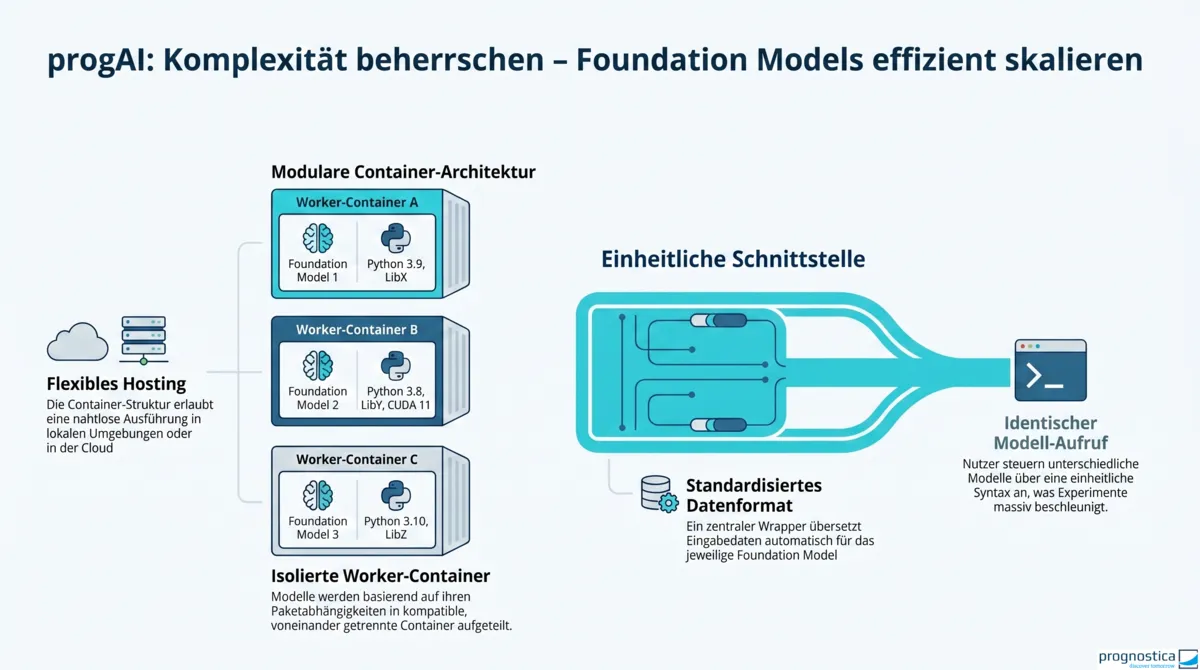
In der Praxis scheitert der Vergleich sowie die produktive Nutzung verschiedener Foundation Models oft nicht an der Theorie, sondern an der technischen Umsetzung. Typische Hürden sind:
- Umfangreiche und teils inkompatible Paketabhängigkeiten, die den Einsatz mehrerer Modelle in einer gemeinsamen Umgebung deutlich erschweren oder sogar unmöglich machen können.
- Unterschiedliche Eingabeformate, was häufig eine individuelle Datenaufbereitung für die Erstellung von Forecasts nötig macht.
- Voneinander abweichende Anforderungen für Forecasting, Finetuning und Kovariaten.
Um diese Exploration von Foundation Models zu vereinfachen und belastbar die zentrale Frage beantworten zu können, auf welcher Grundlage sich entscheiden lässt, für welche Zeitreihen ein Umstieg auf Forecasts aus Foundation Models tatsächlich sinnvoll ist, haben wir mit unserem öffentlich zugänglichen progAI-Repository eine technische Grundlage geschaffen, die viele der oben genannten Hürden reduziert. Die Modelle werden dort abhängig von der Kompatibilität ihrer Paketabhängigkeiten auf unterschiedliche Worker verteilt, die sich auch lokal hosten lassen. Auch die individuelle Datenaufbereitung entfällt für Nutzer weitgehend, da Wrapper ein Standard-Datenformat im Hintergrund für die jeweiligen Foundation Models vorbereiten. Das erleichtert sowohl die Forecast-Erstellung als auch Finetuning-Workflows und die Einbindung von Kovariaten.
Der eigentliche Mehrwert liegt dabei nicht nur im bequemeren Modellaufruf, sondern darin, verschiedene Modelle und Varianten unter vergleichbaren Bedingungen testen zu können.
Wie lassen sich Foundation Models sinnvoll evaluieren?
Für die Bewertung von Foundation Models reicht es in der Praxis selten aus, nur auf eine globale Durchschnittsmetrik zu schauen. Aussagekräftiger wird die Evaluation, wenn Zeitreihen nach Eigenschaften gruppiert und getrennt analysiert werden, zum Beispiel nach
- Historienlänge,
- Saisonalität,
- Trendverhalten,
- Intermittenz,
- Volatilität oder Ausreißeranfälligkeit.
So lässt sich gezielt erkennen, bei welchen Zeitreihenklassen Foundation Models besonders gut performen und wo klassische Verfahren weiterhin überlegen sind. Für identifizierte Gruppen können die Forecasts dann entweder direkt übernommen oder in Ensemble-Ansätzen mit bestehenden Verfahren kombiniert werden.
Dieser Blick auf Teilgruppen ist auch deshalb wichtig, weil ein Modellwechsel nicht nur Genauigkeitsgewinne bringen kann. Oft spielen ebenso Laufzeit, Wartbarkeit und die Vereinfachung des gesamten Forecasting-Workflows eine Rolle. Wird später ein leistungsfähigeres Modell verfügbar, kann ein gut abstrahierter Workflow einen Wechsel zudem stark beschleunigen, wie etwa bei Chronos 2, wo beim Funktionsaufruf lediglich ein anderer Modellparameter gesetzt werden muss.
Fazit: Zero-Shot als Startpunkt, Finetuning als Hebel
Foundation Models eröffnen im Forecasting einen neuen Zugang: Statt für jede Zeitreihe oder jeden Datensatz eine eigene Modellwelt aufzubauen, kann ein vortrainiertes Modell bereits ohne zusätzliche Anpassung sinnvolle Forecasts liefern. Genau deshalb ist Zero-Shot-Forecasting ein sehr guter Startpunkt für die Exploration.
Sobald der Anwendungsfall produktiv wird und datensatzspezifische Muster klar erkennbar sind, wird Finetuning interessant. Dann geht es nicht mehr nur um schnelle Einsetzbarkeit, sondern um gezielte Spezialisierung auf die eigene Datenbasis und die geschäftlich relevante Verbesserung der Prognosequalität.
Unterm Strich gilt: Zero-Shot ist oft der richtige Einstieg, Finetuning der gezielte Performance-Hebel. Welche Variante sich lohnt, entscheidet sich nicht abstrakt auf Benchmarks, sondern auf den eigenen Daten, mit einer sauberen Evaluation und klaren Anforderungen an den Forecasting-Use-Case.