Foundation models are considered the next major step forward in forecasting: a pre-trained model is expected to deliver usable predictions across very different time series without requiring a separate model to be trained for each one. In practice, however, a key question quickly emerges: is zero-shot forecasting enough, or is it worth fine-tuning on your own dataset?
In this article, we explain what foundation models in forecasting are, how they differ from classical methods, and under which conditions fine-tuning delivers real added value.
What are foundation models in forecasting?
How do foundation models differ from classical forecasting methods?
Which foundation models are currently shaping forecasting?
When does fine-tuning pay off, and when is zero-shot forecasting enough?
How are foundation models in forecasting evolving?
How can companies find the right foundation model?
Conclusion: Zero-shot as the starting point, fine-tuning as the lever
What are foundation models in forecasting?
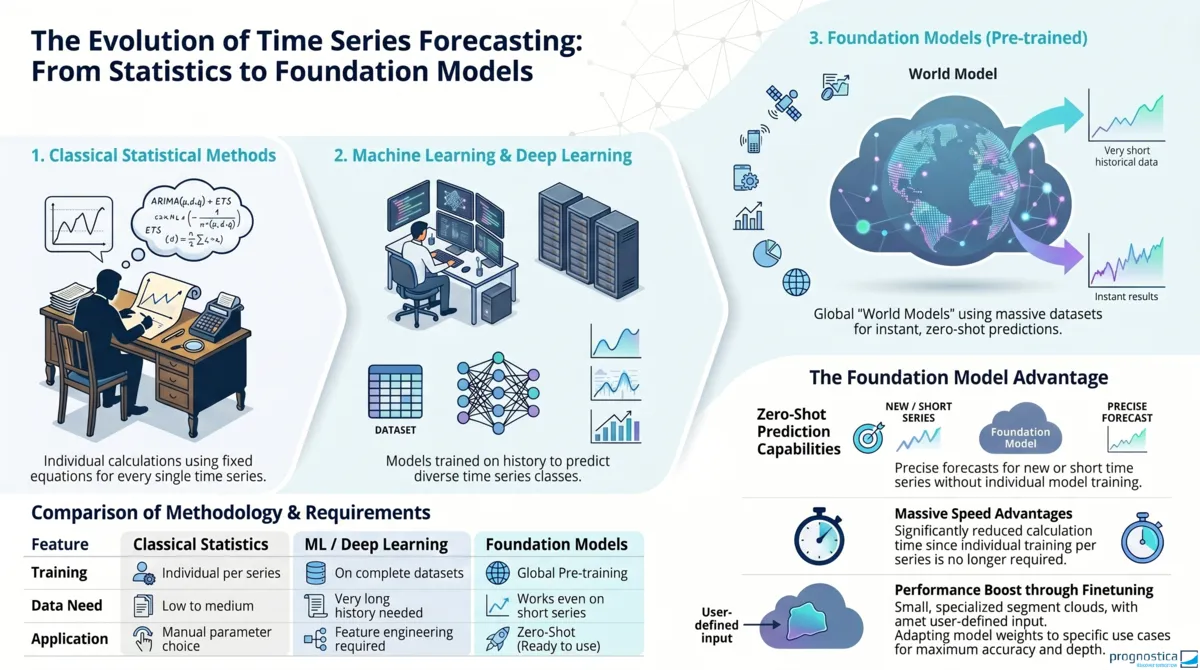
Put simply, foundation models in forecasting are something like large language models (LLMs) for time series: large, pre-trained models that learn general patterns from extensive datasets and can therefore be applied to many different forecasting tasks. While LLMs process language, foundation models recognize typical structures in time series, such as trends, seasonality, and recurring patterns.
This development was made possible in part by the Transformer architecture with its parallelizable self-attention mechanism, which became widely known through applications like ChatGPT starting in November 2022. The success of this approach, based on very large models with vast numbers of parameters and enormous training datasets, has shown that large, pre-trained models are suitable not only for text but also for other data types, such as images, audio, and, indeed, time series.
In forecasting, such models are trained on large and ideally diverse time series datasets. The goal is to deliver competitive predictions across a wide range of time series classes without having to train a dedicated model for each individual series.
How do foundation models differ from classical forecasting methods?
To understand what makes foundation models in forecasting special, it helps to first look at the methods that have typically been used in time series forecasting so far. Classical statistical methods such as ARIMA (Autoregressive Integrated Moving Average) are trained individually for each time series. They learn relationships from the history of the respective series and encode them in model parameters, such as the influence of past values or seasonal effects. Based on these parameters, future values of that exact time series can then be calculated.
With the rise of machine learning, additional approaches emerged. Feature-based global models such as regression trees or random forests are no longer trained on each time series separately but on an entire dataset of time series. However, the model must still be supplied with suitable features manually. Determining which features are useful requires domain knowledge and experience.
In deep learning models such as LSTMs (Long Short-Term Memory), these features are no longer defined by hand but learned directly from the temporal sequence by adjusting the weights of the neural network. For this automatic learning to work well, however, a significantly longer history is usually required than with classical or feature-based methods. That limits the range of applications for these otherwise often very powerful models. In addition, after training, deep learning models are usually strongly tailored to the time series in the training dataset. Without retraining, they therefore should not simply be transferred to completely different classes of time series. A time series class refers to groups of time series with similar properties, such as intermittent time series or seasonal time series.
Foundation models differ from this in several ways:
They are also global models but do not require manually engineered features. The history of the time series is sufficient as input to generate predictions. Characteristics such as trend or seasonality therefore do not first need to be calculated separately from the data and passed to the model.
Foundation models can also be applied to very short time series. This is possible because they are pre-trained on large and ideally diverse corpora of time series intended to cover different time series classes. The patterns learned in the process are stored in the model parameters and can then be transferred to new time series as well.
If a foundation model is used to forecast a new time series, no additional training on that specific time series is required in many cases. Instead, the forecast can be generated solely on the basis of its history. This is known as a zero-shot forecast. This is exactly the core promise of foundation models in forecasting: in principle, a single model can be used for very different forecasting tasks and time series classes. Forecast generation is then also very fast because, unlike traditional approaches, multiple models often do not need to be trained and compared based on their historical performance, which makes computation relatively more expensive.
Which foundation models are currently shaping forecasting?
Over time, many providers have released foundation models for forecasting. It is not possible to provide a comprehensive overview here. Instead, we provide a brief look at some key ideas and technical approaches that distinguish these models from one another.
TimesFM: patches instead of individual values
One of the early challenges for foundation models for time series was the large context length. Time series with daily, hourly, or even finer granularity often contain more than 1,000 data points. To represent dependencies over longer periods as well, Google’s TimesFM groups multiple consecutive values of a time series into so-called patches and treats them as tokens. Tokens are the smallest units the model works on. Unlike LLMs, where individual words or word parts are tokenized, tokens here correspond to entire segments of a time series. Forecasts are also output patch by patch, with the output patches usually being longer than the input patches. To preserve short-term dynamics despite this compression, the patches overlap. This can be roughly compared to how convolution operations work in image processing.
Instead of viewing time series as a sequence of individual data points, the idea is to translate the time series into a language with its own vocabulary. In that language, a sentence might look something like this: “The time series values are already fairly high. Now they are moving even higher.”
Chronos: quantization for continuous values
Time series values are continuous and can theoretically take on infinitely many forms. Amazon’s Chronos addresses this by first scaling the values and then quantizing them into discrete value ranges. The time series is thereby translated into a sequence of discrete tokens that can be modeled similarly to language. For forecasting, the output tokens are then mapped back into the original value range.
TimeGPT and synthetic training data
Another important aspect is the composition of the training data. As with foundation models of any kind, publicly available datasets are also used in forecasting. Nixtla’s TimeGPT, for example, was trained on a very large number of time series from different domains. In addition, synthetic data is often used, for example in the context of data augmentation, to cover underrepresented time series classes more effectively. Such synthetic time series do not come from real-world use cases but are generated according to rules, for example as sine curves with predefined amplitude, frequency, and phase.
However, particularly for time series with external covariates, there is still a lack of suitable training data. As a result, there is currently no foundation model that systematically incorporates covariates directly during pre-training.
Why foundation models are currently difficult to compare
At present, it is hardly possible to say definitively which foundation model is the best for forecasting. There are several reasons for this:
- New models and model versions appear at high speed.
- Evaluations often rely on publicly accessible benchmark datasets, whose validity is only limited. Once an initial evaluation has been published, the benchmark datasets are publicly available as well. That increases the likelihood that newer models were trained on at least parts of those benchmarks. This potentially gives them an unfair advantage over older models that were developed before the benchmark was published.
- Not all providers disclose the data on which their models were trained. Because the composition of training data can represent a competitive advantage, it often remains unclear whether a model is actually better or whether it has already seen parts of the benchmark dataset.
In response, new benchmarks are continuously assembled and published to counteract such distortions. But that also makes comparison even more confusing: the more benchmarks emerge, the harder it becomes to compare models fairly and consistently over time.
When does fine-tuning pay off, and when is zero-shot forecasting enough?
Foundation models can already deliver useful forecasts without any additional adaptation. Whether zero-shot forecasting is sufficient or fine-tuning makes sense depends primarily on the characteristics of your own dataset and the requirements for forecast quality.
When is zero-shot forecasting without fine-tuning enough?
To achieve broad applicability, foundation models are pre-trained on datasets that are as diverse as possible. The goal is to enable passable forecasts across a wide range of time series classes even without additional adaptation. Zero-shot forecasting can therefore be sufficient in particular when
- the pre-trained model already achieves adequate forecast quality on your own dataset,
- the use case does not exhibit highly specific patterns, and
- fast, resource-efficient deployment is the main priority.
This is especially relevant in early evaluation phases or when forecasts need to be generated for many different time series with as little implementation effort as possible.
When does fine-tuning make sense?
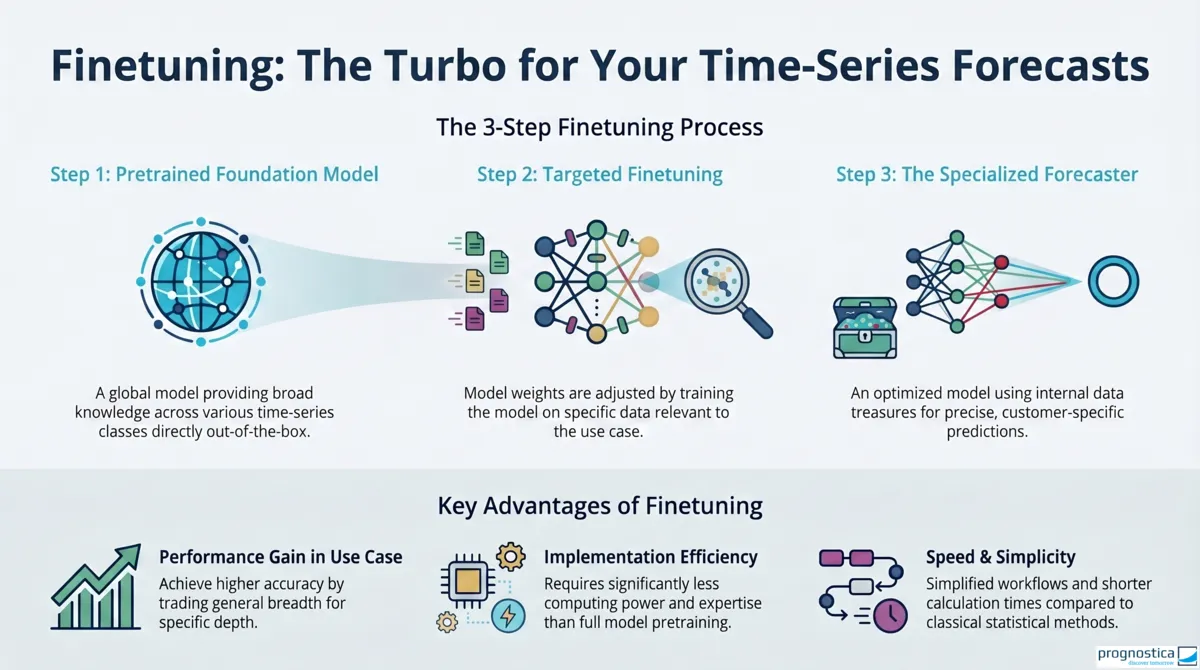
In production use, your own dataset is often much more homogeneous than the data basis on which a foundation model was pre-trained. Perhaps all time series have the same granularity, come from the same industry, or repeatedly contain very similar, dataset-specific patterns. In such cases, fine-tuning can make sense.
During fine-tuning, the model weights are specifically adapted to your own application dataset in a downstream training step. Put simply, part of the generalization capability is traded for better specialization to your own use case.
Fine-tuning is particularly worthwhile when
- additional performance gains are business-relevant,
- your dataset has clearly delineated characteristics,
- sufficient quality-assured training data is available for the target context, and
- zero-shot performance is already usable but still falls short of the required quality level.
Even today, we have shown in various projects that fine-tuning can unlock hidden potential in internal company data.
What matters here is this: fine-tuning is significantly less expensive than the original pre-training of a foundation model, but it is still not automatic. Data preparation, clean evaluation logic, and the choice of suitable metrics remain critical.
How are foundation models in forecasting evolving?
Development is currently progressing in several directions at the same time:
One important trend is multimodal foundation models. These models process not only the time series themselves but also additional information such as texts, events, or images. This is especially relevant for companies because valuable forecasting signals often do not exist in classical time series form.
In addition, approaches are emerging that aim to make it easier to integrate external drivers into forecasting. These include comparatively lightweight adapters placed upstream of the actual model. Cross-learning of dataset-specific patterns is also becoming more important and has already been taken up in Chronos 2, for example: very short time series can then benefit more strongly from similar time series within the same product group or category.
There are therefore many signs that foundation models in forecasting will become not only more powerful but also more flexible to use in the future. For companies in particular, it is likely to become increasingly worthwhile to unlock the potential of their own data in combination with these models in a targeted way.
How can companies find the right foundation model?
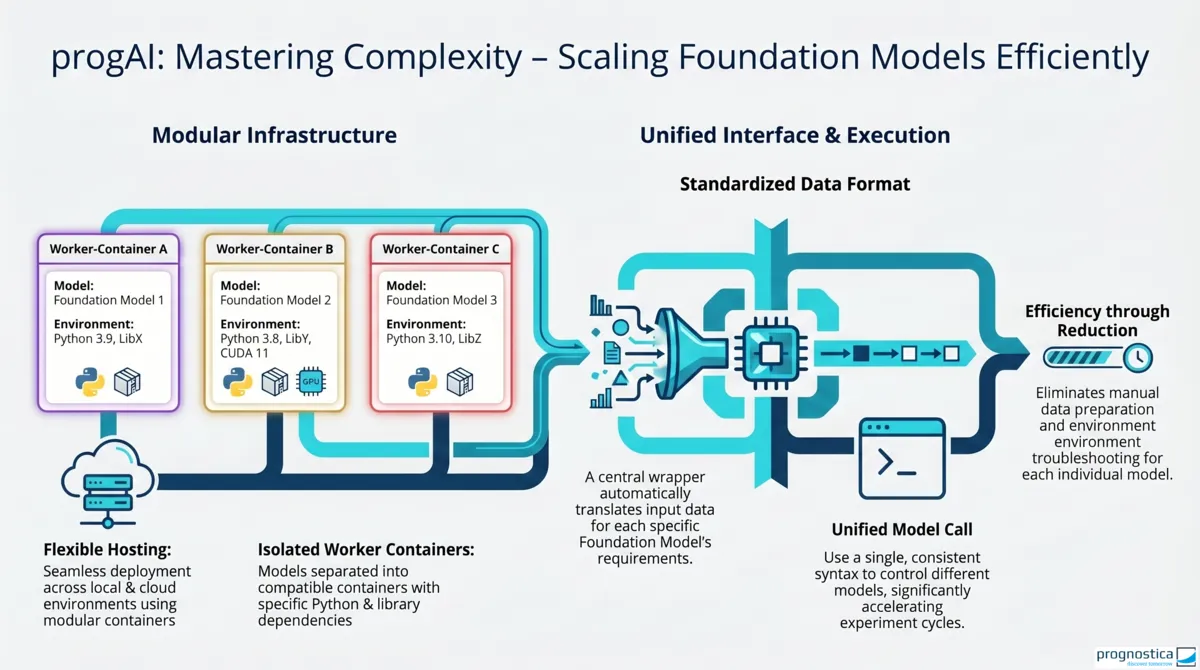
In practice, comparing and productively using different foundation models often fails not because of theory but because of technical implementation. Typical hurdles include:
- Extensive and sometimes incompatible package dependencies, which can make it much harder or even impossible to use multiple models in a shared environment.
- Different input formats, which often require individual data preparation for forecast generation.
- Diverging requirements for forecasting, fine-tuning, and covariates.
To simplify this exploration of foundation models and answer the key question in a robust way, on what basis can companies decide whether switching to forecasts generated by foundation models actually makes sense for specific time series, we created a technical foundation with our publicly accessible progAI repository that reduces many of the hurdles mentioned above. Depending on the compatibility of their package dependencies, the models are distributed across different workers, which can also be hosted locally. Users are also largely spared model-specific data preparation because wrappers prepare a standard data format in the background for the respective foundation models. This simplifies forecast generation, fine-tuning workflows, and the integration of covariates.
The real added value lies not only in easier model invocation but in being able to test different models and variants under comparable conditions.
How can foundation models be evaluated in a meaningful way?
In practice, it is rarely enough to look only at a single global average metric when evaluating foundation models. The evaluation becomes more informative when time series are grouped and analyzed separately according to their properties, for example by
- history length,
- seasonality,
- trend behavior,
- intermittency,
- volatility, or susceptibility to outliers.
This makes it possible to identify precisely for which time series classes foundation models perform particularly well and where classical methods still remain superior. For identified groups, the forecasts can then either be adopted directly or combined with existing methods in ensemble approaches.
This view of subgroups is also important because a model change may bring more than just accuracy gains. Runtime, maintainability, and simplification of the overall forecasting workflow often matter as well. And if a more powerful model becomes available later, a well-abstracted workflow can greatly accelerate the switch, as with Chronos 2, where only a different model parameter needs to be set in the function call.
Conclusion: zero-shot as the starting point, fine-tuning as the lever
Foundation models open up a new approach to forecasting: instead of building a separate model world for each time series or dataset, a pre-trained model can already deliver useful forecasts without additional adaptation. That is exactly why zero-shot forecasting is a very good starting point for exploration.
As soon as the use case moves into production and dataset-specific patterns become clearly visible, fine-tuning becomes interesting. At that point, the focus is no longer only on fast deployment but on targeted specialization to your own data basis and on business-relevant improvements in forecast quality.
The bottom line is: zero-shot is often the right starting point, and fine-tuning is the targeted performance lever. Which option is worthwhile is not decided abstractly on benchmarks but on your own data, with a clean evaluation and clear requirements for the forecasting use case.